Note: This is a cross-post of the original publication on contextsdk.com.
This is the second blog post covering various machine learning (ML) concepts of iOS apps, be sure to read part 1 first. Initially this was supposed to be a 2-piece series, but thanks to the incredible feedback of the first one, we’ve decided to cover even more on this topic, and go into more detail.
Introduction
For some apps it may be sufficient to train a ML (machine learning) model once, and ship it with the app itself. However, most mobile apps are way more dynamic than that, constantly changing and evolving. It is therefore important to be able to quickly adapt and improve your machine learning models, without having to do a full app release, and go through the whole App Store release & review process.
In this series, we will explore how to operate machine learning models directly on your device instead of relying on external servers via network requests. Running models on-device enables immediate decision-making, eliminates the need for an active internet connection, and can significantly lower infrastructure expenses.
In the example of this series, we’re using a model to make a decision on when to prompt the user to upgrade to the paid plan based on a set of device-signals, to reduce user annoyances, while increasing our paid subscribers.
Step 1: Shipping a base-model with your app’s binary
We believe in the craft of beautiful, reliable and fast mobile apps. Running machine-learning devices on-device makes your app responsive, snappy and reliable. One aspect to consider is the first app launch, which is critical to prevent churn and get the user hooked to your app.
To ensure your app works out of the box right after its installation, we recommend shipping your pre-trained CoreML file with your app. Our part 1 covers how to easily achieve this with Xcode
Step 2: Check for new CoreML updates
Your iOS app needs to know when a new version of the machine learning file is available. This is as simple as regularly sending an empty network request to your server. Your server doesn’t need to be sophisticated, we initially started with a static file host (like S3, or alike) that we update whenever we have a new model ready.
The response could use whatever versioning you prefer:
- A version number of your most recent model
- The timestamp your most recent model was trained
- A checksum
- A randomly generated UUID
Whereas the iOS client would compare the version number of most recently downloaded model with whatever the server responds with. Which approach you choose, is up to you, and your strategy on how you want to rollout, monitor and version your machine learning models.
Over time, you most likely want to optimize the number of network requests. Our approach combines a smart mechanism where we’d combine the outcome collection we use to train our machine learning models with the model update checks, while also leveraging a flushing technique to batch many events together to minimize overhead and increase efficiency.
Ideally, the server’s response already contains the download URL of the latest model, here is an example response:
{
"url": "https://krausefx.github.io/CoreMLDemo/models/80a2-82d1-bcf8-4ab5-9d35-d7f257c4c31e.mlmodel"
}
The above example is a little simplified, and we’re using the model’s file name as our version to identify each model.
You’ll also need to consider which app version is supported. In our case, a new ContextSDK version may implement additional signals that are used as part of our model. Therefore we provide the SDK version as part of our initial polling request, and our server responds with the latest model version that’s supported.
First, we’re doing some basic scaffolding, creating a new ModelDownloadManager class:
import Foundation
import CoreML
class ModelDownloadManager {
private let fileManager: FileManager
private let modelsFolder: URL
private let modelUpdateCheckURL = "https://krausefx.github.io/CoreMLDemo/latest_model_details.json"
init(fileManager: FileManager = .default) {
self.fileManager = fileManager
if let folder = fileManager.urls(for: .applicationSupportDirectory, in: .userDomainMask).first?.appendingPathComponent("context_sdk_models") {
self.modelsFolder = folder
try? fileManager.createDirectory(at: folder, withIntermediateDirectories: true)
} else {
fatalError("Unable to find or create models folder.") // Handle this more gracefully
}
}
}
And now to the actual code: Downloading the model details to check if a new model is available:
internal func checkForModelUpdates() async throws {
guard let url = URL(string: modelUpdateCheckURL) else {
throw URLError(.badURL)
}
let (data, _) = try await URLSession.shared.data(from: url)
guard let jsonObject = try JSONSerialization.jsonObject(with: data) as? [String: Any],
let modelDownloadURLString = jsonObject["url"] as? String,
let modelDownloadURL = URL(string: modelDownloadURLString) else {
throw URLError(.cannotParseResponse)
}
try await downloadIfNeeded(from: modelDownloadURL)
}
Step 3: Download the latest CoreML file
If a new CoreML model is available, your iOS app now needs to download the latest version. You can use any method of downloading the static file from your server:
// It's important to immediately move the downloaded CoreML file into a permanent location
private func downloadCoreMLFile(from url: URL) async throws -> URL {
let (tempLocalURL, _) = try await URLSession.shared.download(for: URLRequest(url: url))
let destinationURL = modelsFolder.appendingPathComponent(tempLocalURL.lastPathComponent)
try fileManager.moveItem(at: tempLocalURL, to: destinationURL)
return destinationURL
}
Considering Costs
Depending on your user-base, infrastructure costs will be a big factor on how you’re gonna implement the on-the-fly update mechanism.
For example, an app with 5 Million active users, and a CoreML file size of 1 Megabyte, would generate a total data transfer of 5 Terabyte. If you were to use a simple AWS S3 bucket directly with $0.09 per GB egress costs, this would yield costs of about $450 for each model rollout (not including the free tier).
As part of this series, we will talk about constantly rolling out new, improved challenger models, running various models in parallel, and iterating quickly, paying this amount isn’t a feasible solution.
One easy fix for us was to leverage CloudFlare R2, which is faster and significantly cheaper. The same numbers as above costs us less than $2, and would be completely free if we include the free tier.
Step 4: Compile the CoreML file on-device
After successfully downloading the CoreML file, you need to compile it on-device. While this sounds scary, Apple made it a seamless, easy and safe experience. Compiling the CoreML file on-device is a requirement, and ensures that the file is optimized for the specific hardware it runs on.
private func compileCoreMLFile(at localFilePath: URL) throws -> URL {
let compiledModelURL = try MLModel.compileModel(at: localFilePath)
let destinationCompiledURL = modelsFolder.appendingPathComponent(compiledModelURL.lastPathComponent)
try fileManager.moveItem(at: compiledModelURL, to: destinationCompiledURL)
try fileManager.removeItem(at: localFilePath)
return destinationCompiledURL
}
You are responsible for the file management, including that you store the resulting ML file into a permanent location. In general, file management on iOS can be a little tedious, covering all the various edge cases.
You can also find the official Apple Docs on Downloading and Compiling a Model on the User’s Device.
Step 5: Additional checks and clean-ups
We don’t yet have a logic on how we decide if we want to download the new model. In this example, we’ll do something very basic: each model’s file-name is a unique UUID. All we need to do is to check if a model under the exact file name is available locally:
private func downloadIfNeeded(from url: URL) async throws {
let lastPathComponent = url.lastPathComponent
// Check if the model file already exists (for this sample project we use the unique file name as identifier)
if let localFiles = try? fileManager.contentsOfDirectory(at: modelsFolder, includingPropertiesForKeys: nil),
localFiles.contains(where: { $0.lastPathComponent == lastPathComponent }) {
// File exists, you could add a version check here if versions are part of the file name or metadata
print("Model already exists locally. No need to download.")
} else {
let downloadedURL = try await downloadCoreMLFile(from: url) // File does not exist, download it
let compiledURL = try compileCoreMLFile(at: downloadedURL)
try deleteAllOutdatedModels(keeping: compiledURL.lastPathComponent)
print("Model downloaded, compiled, and old models cleaned up successfully.")
}
}
Of course we want to be a good citizen, and delete all older models from the local storage. Also, for this sample project, this is required, as we’re using UUIDs for versioning, meaning the iOS client actually doesn’t know about which version is higher. For sophisticated systems it’s quite common to not have this transparency to the client, as the backend may be running multiple experiments and challenger models in parallel across all clients.
private func deleteAllOutdatedModels(keeping recentModelFileName: String) throws {
let urlContent = try fileManager.contentsOfDirectory(at: modelsFolder, includingPropertiesForKeys: nil, options: .skipsHiddenFiles)
for fileURL in urlContent where fileURL.lastPathComponent != recentModelFileName {
try fileManager.removeItem(at: fileURL)
}
}
Step 6: Execute the newly downloaded CoreML file instead of the bundled version
Now all that’s left is to automatically switch between the CoreML file that we bundled within our app, and the file we downloaded from our servers, whereas we’d always want to prefer the one we downloaded remotely.
In our ModelDownloadManager, we want an additional function that exposes the model we want to use. This can either be the bundled CoreML model, or the CoreML model downloaded most recently over-the-air
internal func latestModel() -> MyFirstCustomModel? {
let fileManagerContents = (try? fileManager.contentsOfDirectory(at: modelsFolder, includingPropertiesForKeys: nil)) ?? []
if let latestFileURL = fileManagerContents.sorted(by: { $0.lastPathComponent > $1.lastPathComponent }).first,
let otaModel = try? MyFirstCustomModel(contentsOf: latestFileURL) {
return otaModel
} else if let bundledModel = try? MyFirstCustomModel(configuration: MLModelConfiguration()) {
return bundledModel // Fallback to the bundled model if no downloaded model exists
}
return nil
}
There are almost no changes needed to our code base from part 1.
Instead of using the MyFirstCustomModel initializer directly, we now need to use the newly created .latestModel() method.
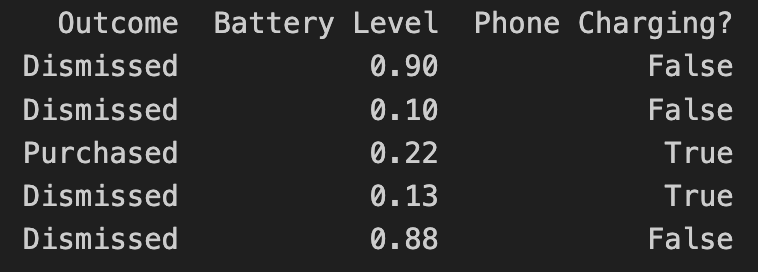
let batteryLevel = UIDevice.current.batteryLevel
let batteryCharging = UIDevice.current.batteryState == .charging || UIDevice.current.batteryState == .full
do {
let modelInput = MyFirstCustomModelInput(input: [
Double(batteryLevel),
Double(batteryCharging ? 1.0 : 0.0)
])
if let currentModel = modelDownloadManager.latestModel(),
let modelMetadata = currentModel.model.modelDescription.metadata[.description] {
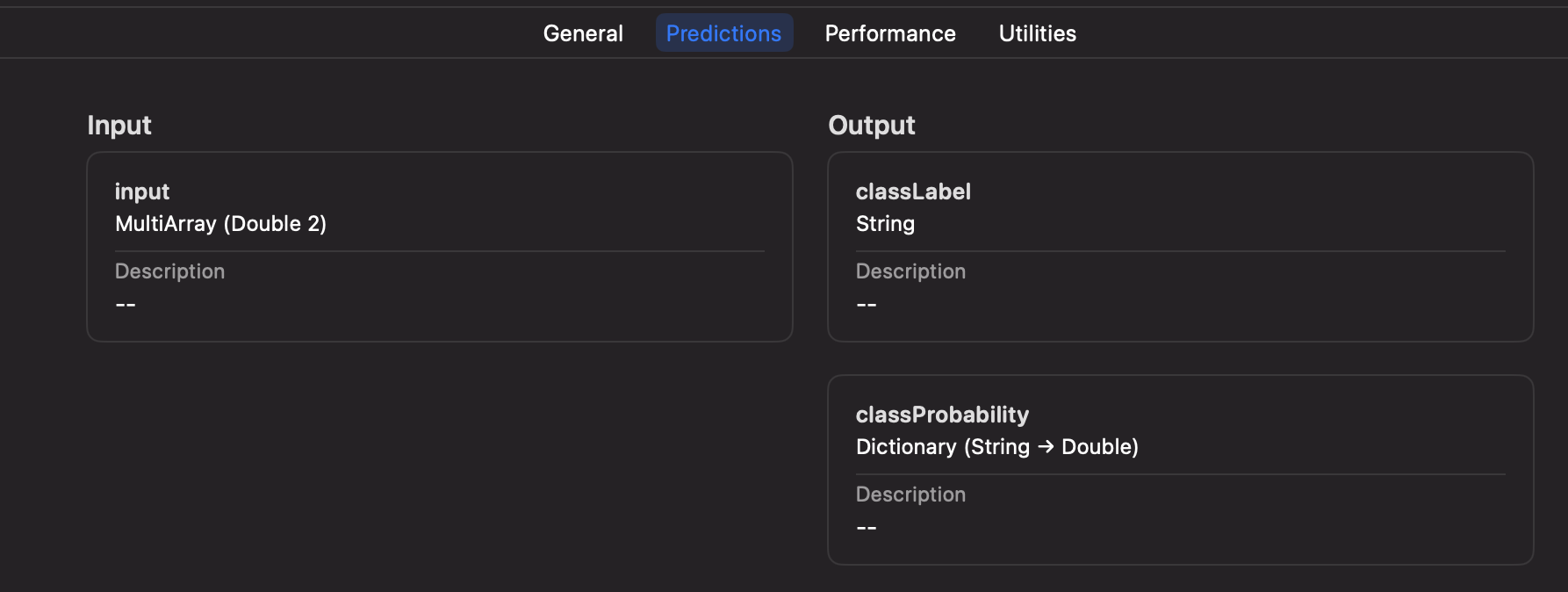
let result = try currentModel.prediction(input: modelInput)
let classProbabilities = result.featureValue(for: "classProbability")?.dictionaryValue
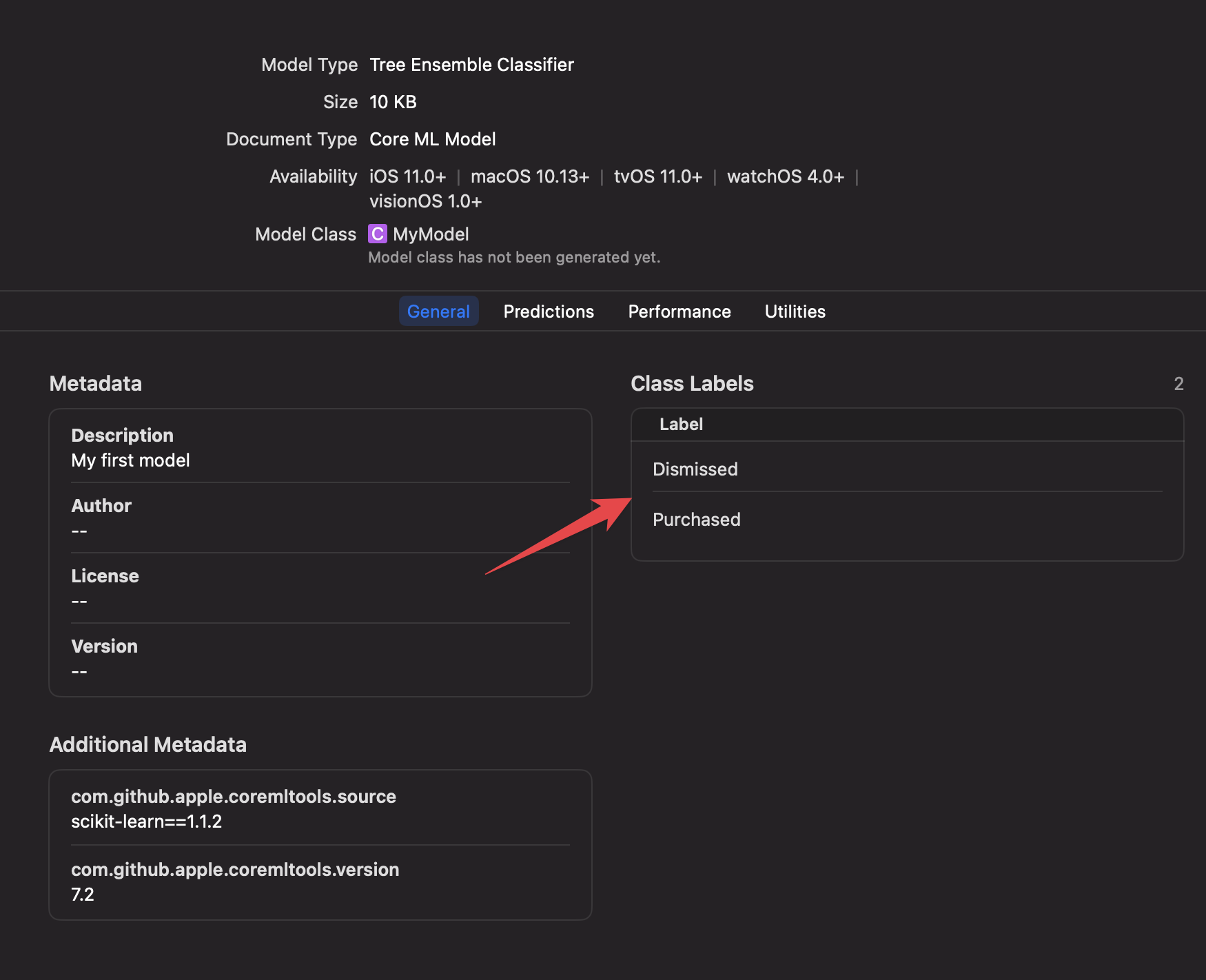
let upsellProbability = classProbabilities?["Purchased"]?.doubleValue ?? -1
showAlertDialog(message:("Chances of Upsell: \(upsellProbability), executed through model \(modelMetadata)"))
} else {
showAlertDialog(message:("Could not run CoreML model"))
}
} catch {
showAlertDialog(message:("Error running CoreML file: \(error)"))
}
Step 7: Decide when you want to trigger the update check
The only remaining code that’s left: triggering the update check. When you do that will highly depend on your app, and the urgency in which you want to update your models.
Task {
do {
try await modelDownloadManager.checkForModelUpdates()
showAlertDialog(message:("Model update completed successfully."))
} catch {
// Handle possible errors here
showAlertDialog(message:("Failed to update model: \(error.localizedDescription)"))
}
}
Demo App
As part of this series, we’ve built out a demo app that shows all of this end-to-end in action. You can find it available here on GitHub: https://github.com/KrauseFx/CoreMLDemo:
What’s next?
Today we’ve covered how you can roll out new machine learning models directly to your users’ iPhones, running them directly on their ML-optimized hardware. Using this approach you can make decisions on what type of content, or prompts you show based on the user’s context, powered by on-device machine learning execution. Updating CoreML files quickly, on-the-fly without going through the full App Store release cycle is critical, to quickly react to changing user-behaviors, when introducing new offers in your app, and to constantly improve your app, be it increasing your conversion rates, reducing annoyances and churn, or optimizing other parts of your app.
This is just the beginning: Next up, we will talk about how to manage the rollout of new ML models, in particular:
- How to safely rollout new models: monitor, pause or rollback faulty models
- How to monitor performance of deployed models
- How to reliably compare performance between models, and the baseline performance
Excited to share more on what we’ve learned when building ContextSDK to power hundreds of machine learning models distributed across more than 25 Million devices.
Note: This is a cross-post of the original publication on contextsdk.com.
]]>










































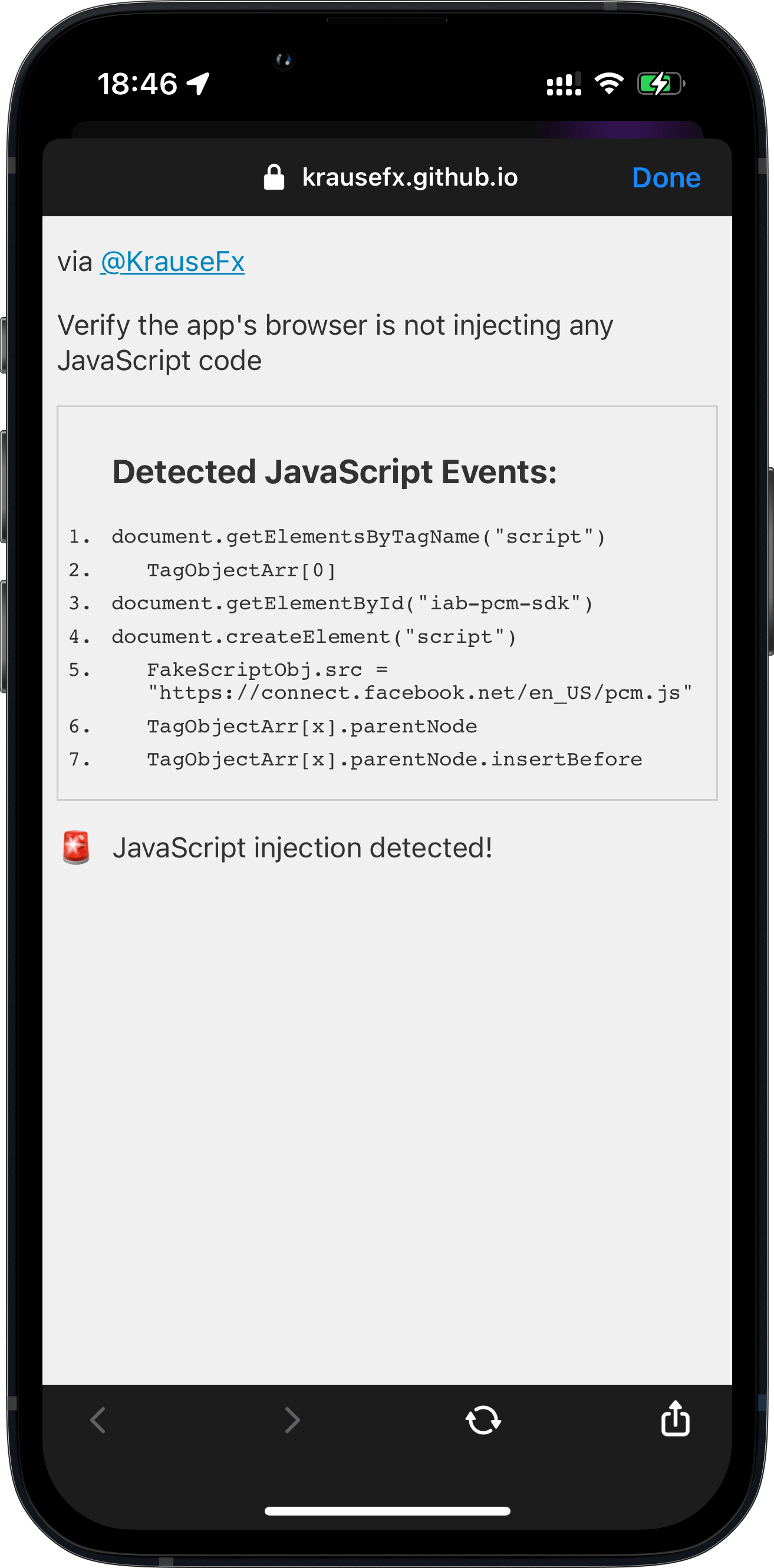
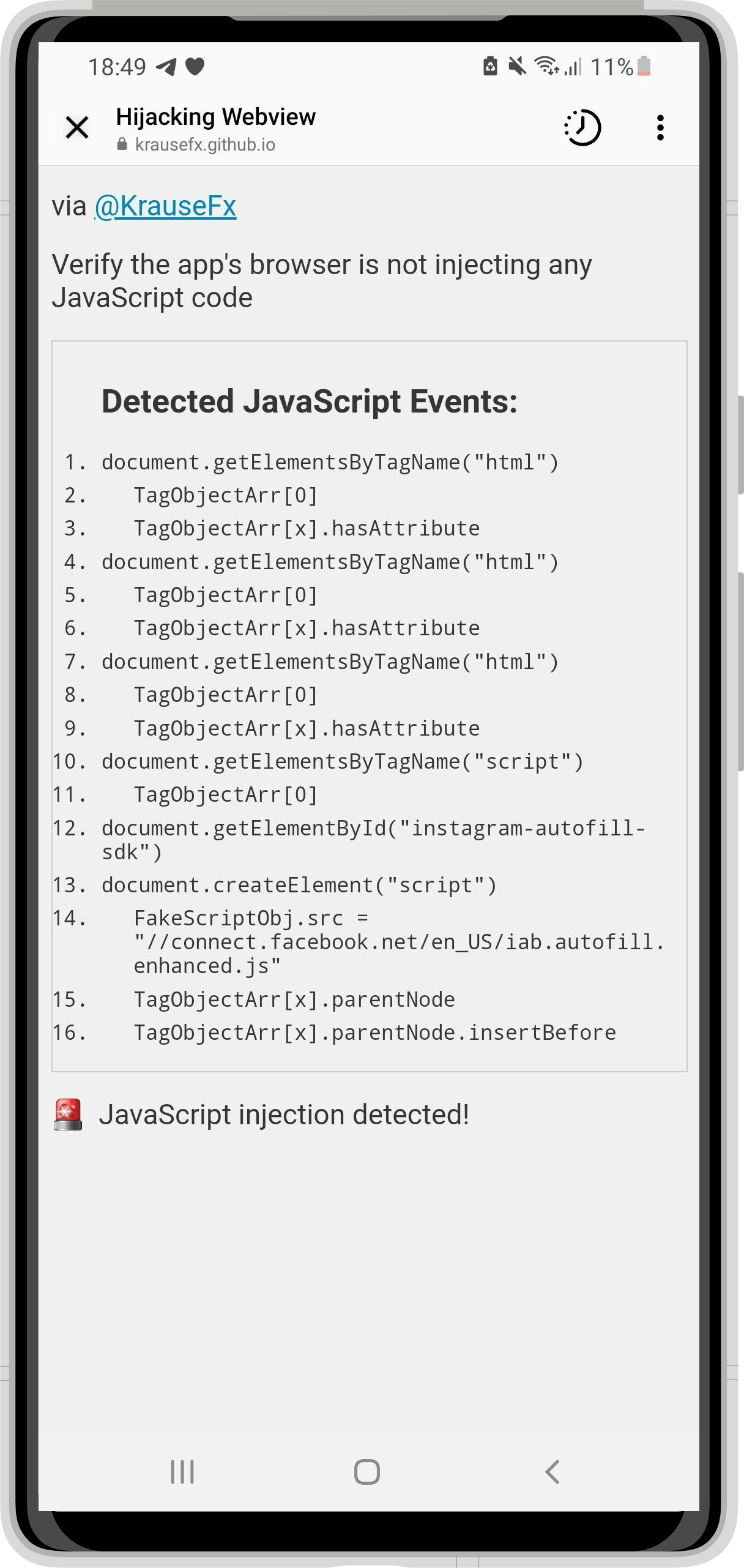
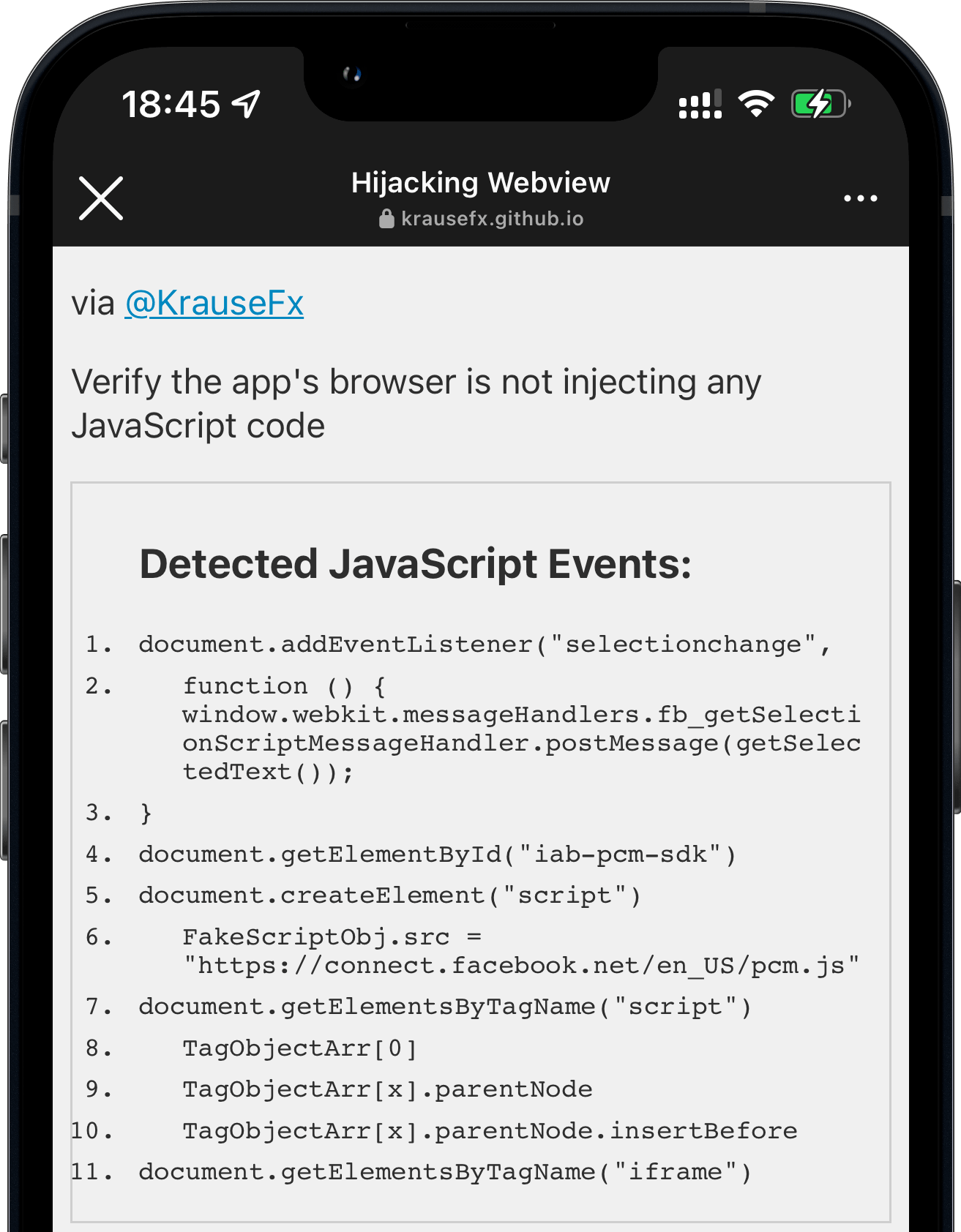
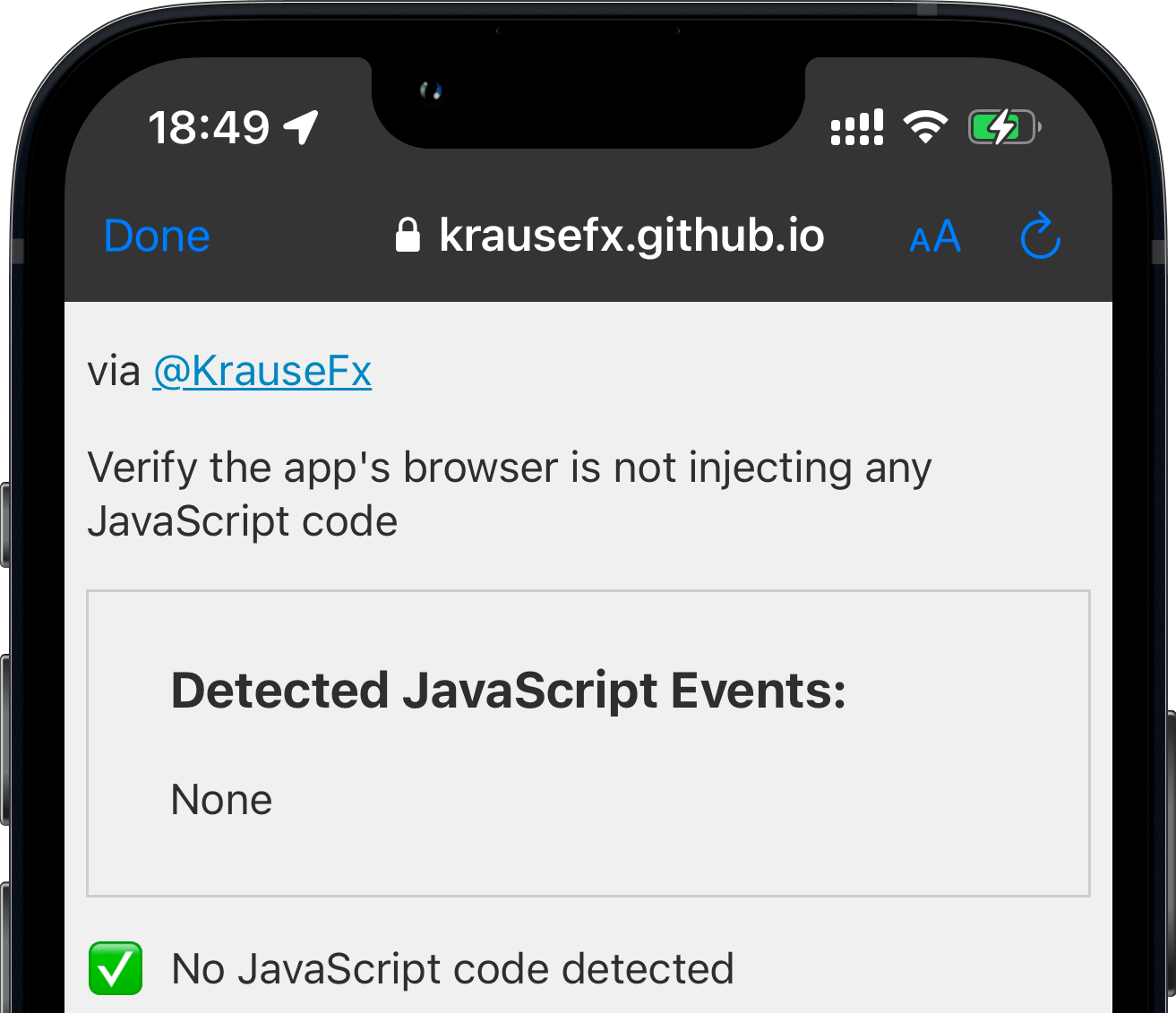
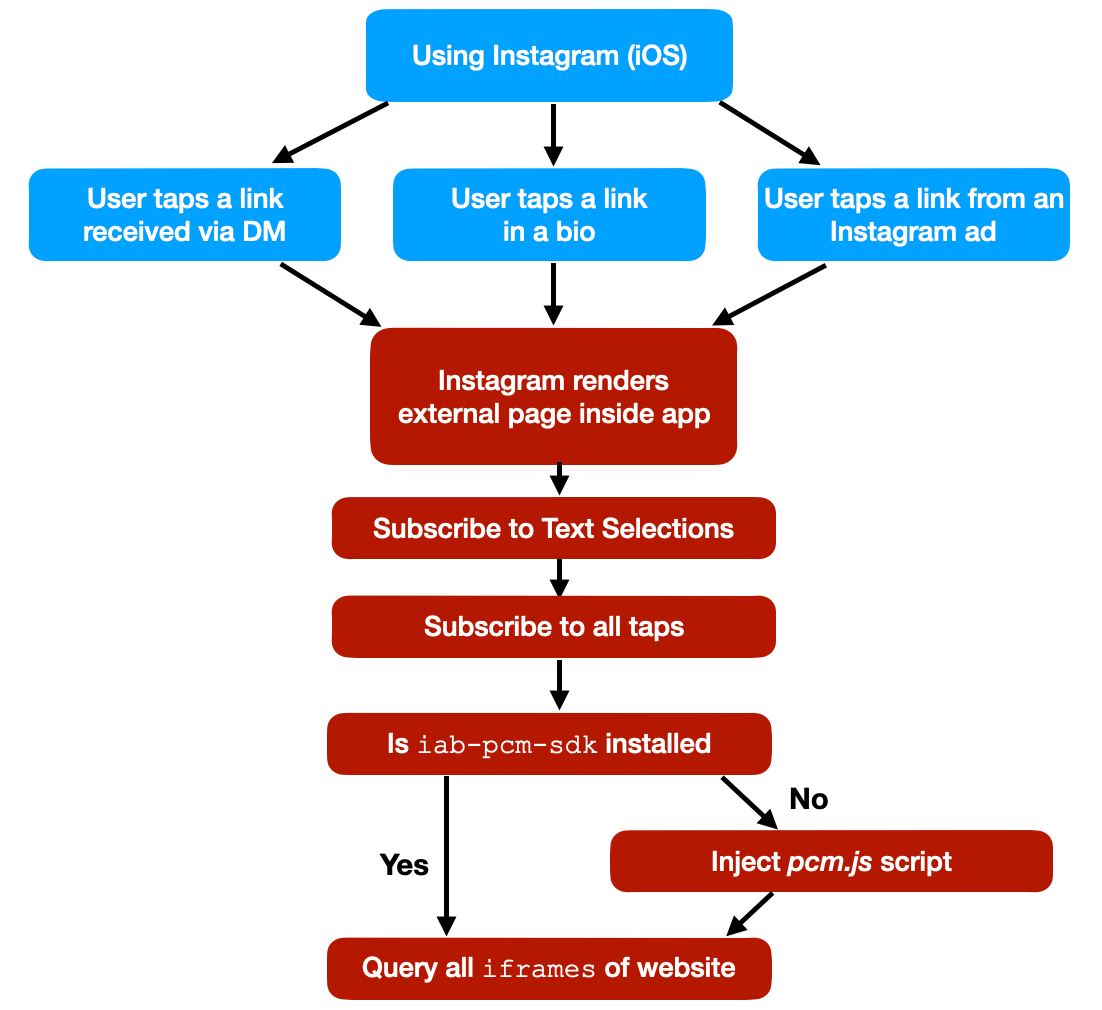
![An iPhone screenshot, showing a website, rendering what commands got executed by the Instagram app in their in-app browser:
Detected JavaScript Events:
1.
document. addEventListener ('selectionchange'
2.
function ()
{
window.webkit.messageHandlers.fb getSelecti
onScriptMessageHandler.postMessage(getSelec
tedText)):
3. }
4.
document. getElementById('iab-pcm-sdk')
5.
document.createElement ('script')
6.
FakeScriptobj.src
'https://connect.facebook.net/en US/pcm.is'
7. document. getElementsByTagName ('script')
8.
TagObjectArr[0]
9.
TagObjectArr[x].parentNode
10.
TagobjectArr[x].parentNode.insertBefore
11.
document.getElementsByTagName('iframe')](https://krausefx.com/assets/posts/injecting-code/instagram_framed.png)