
Safely distribute new Machine Learning models to millions of iPhones over-the-air

Note: This is a cross-post of the original publication on contextsdk.com.
This is the second blog post covering various machine learning (ML) concepts of iOS apps, be sure to read part 1 first. Initially this was supposed to be a 2-piece series, but thanks to the incredible feedback of the first one, we’ve decided to cover even more on this topic, and go into more detail.
Introduction
For some apps it may be sufficient to train a ML (machine learning) model once, and ship it with the app itself. However, most mobile apps are way more dynamic than that, constantly changing and evolving. It is therefore important to be able to quickly adapt and improve your machine learning models, without having to do a full app release, and go through the whole App Store release & review process.
In this series, we will explore how to operate machine learning models directly on your device instead of relying on external servers via network requests. Running models on-device enables immediate decision-making, eliminates the need for an active internet connection, and can significantly lower infrastructure expenses.
In the example of this series, we’re using a model to make a decision on when to prompt the user to upgrade to the paid plan based on a set of device-signals, to reduce user annoyances, while increasing our paid subscribers.
Step 1: Shipping a base-model with your app’s binary
We believe in the craft of beautiful, reliable and fast mobile apps. Running machine-learning devices on-device makes your app responsive, snappy and reliable. One aspect to consider is the first app launch, which is critical to prevent churn and get the user hooked to your app.
To ensure your app works out of the box right after its installation, we recommend shipping your pre-trained CoreML file with your app. Our part 1 covers how to easily achieve this with Xcode
Step 2: Check for new CoreML updates
Your iOS app needs to know when a new version of the machine learning file is available. This is as simple as regularly sending an empty network request to your server. Your server doesn’t need to be sophisticated, we initially started with a static file host (like S3, or alike) that we update whenever we have a new model ready.
The response could use whatever versioning you prefer:
- A version number of your most recent model
- The timestamp your most recent model was trained
- A checksum
- A randomly generated UUID
Whereas the iOS client would compare the version number of most recently downloaded model with whatever the server responds with. Which approach you choose, is up to you, and your strategy on how you want to rollout, monitor and version your machine learning models.
Over time, you most likely want to optimize the number of network requests. Our approach combines a smart mechanism where we’d combine the outcome collection we use to train our machine learning models with the model update checks, while also leveraging a flushing technique to batch many events together to minimize overhead and increase efficiency.
Ideally, the server’s response already contains the download URL of the latest model, here is an example response:
{
"url": "https://krausefx.github.io/CoreMLDemo/models/80a2-82d1-bcf8-4ab5-9d35-d7f257c4c31e.mlmodel"
}
The above example is a little simplified, and we’re using the model’s file name as our version to identify each model.
You’ll also need to consider which app version is supported. In our case, a new ContextSDK version may implement additional signals that are used as part of our model. Therefore we provide the SDK version as part of our initial polling request, and our server responds with the latest model version that’s supported.
First, we’re doing some basic scaffolding, creating a new ModelDownloadManager class:
import Foundation
import CoreML
class ModelDownloadManager {
private let fileManager: FileManager
private let modelsFolder: URL
private let modelUpdateCheckURL = "https://krausefx.github.io/CoreMLDemo/latest_model_details.json"
init(fileManager: FileManager = .default) {
self.fileManager = fileManager
if let folder = fileManager.urls(for: .applicationSupportDirectory, in: .userDomainMask).first?.appendingPathComponent("context_sdk_models") {
self.modelsFolder = folder
try? fileManager.createDirectory(at: folder, withIntermediateDirectories: true)
} else {
fatalError("Unable to find or create models folder.") // Handle this more gracefully
}
}
}
And now to the actual code: Downloading the model details to check if a new model is available:
internal func checkForModelUpdates() async throws {
guard let url = URL(string: modelUpdateCheckURL) else {
throw URLError(.badURL)
}
let (data, _) = try await URLSession.shared.data(from: url)
guard let jsonObject = try JSONSerialization.jsonObject(with: data) as? [String: Any],
let modelDownloadURLString = jsonObject["url"] as? String,
let modelDownloadURL = URL(string: modelDownloadURLString) else {
throw URLError(.cannotParseResponse)
}
try await downloadIfNeeded(from: modelDownloadURL)
}
Step 3: Download the latest CoreML file
If a new CoreML model is available, your iOS app now needs to download the latest version. You can use any method of downloading the static file from your server:
// It's important to immediately move the downloaded CoreML file into a permanent location
private func downloadCoreMLFile(from url: URL) async throws -> URL {
let (tempLocalURL, _) = try await URLSession.shared.download(for: URLRequest(url: url))
let destinationURL = modelsFolder.appendingPathComponent(tempLocalURL.lastPathComponent)
try fileManager.moveItem(at: tempLocalURL, to: destinationURL)
return destinationURL
}
Considering Costs
Depending on your user-base, infrastructure costs will be a big factor on how you’re gonna implement the on-the-fly update mechanism.
For example, an app with 5 Million active users, and a CoreML file size of 1 Megabyte, would generate a total data transfer of 5 Terabyte. If you were to use a simple AWS S3 bucket directly with $0.09 per GB egress costs, this would yield costs of about $450 for each model rollout (not including the free tier).
As part of this series, we will talk about constantly rolling out new, improved challenger models, running various models in parallel, and iterating quickly, paying this amount isn’t a feasible solution.
One easy fix for us was to leverage CloudFlare R2, which is faster and significantly cheaper. The same numbers as above costs us less than $2, and would be completely free if we include the free tier.
Step 4: Compile the CoreML file on-device
After successfully downloading the CoreML file, you need to compile it on-device. While this sounds scary, Apple made it a seamless, easy and safe experience. Compiling the CoreML file on-device is a requirement, and ensures that the file is optimized for the specific hardware it runs on.
private func compileCoreMLFile(at localFilePath: URL) throws -> URL {
let compiledModelURL = try MLModel.compileModel(at: localFilePath)
let destinationCompiledURL = modelsFolder.appendingPathComponent(compiledModelURL.lastPathComponent)
try fileManager.moveItem(at: compiledModelURL, to: destinationCompiledURL)
try fileManager.removeItem(at: localFilePath)
return destinationCompiledURL
}
You are responsible for the file management, including that you store the resulting ML file into a permanent location. In general, file management on iOS can be a little tedious, covering all the various edge cases.
You can also find the official Apple Docs on Downloading and Compiling a Model on the User’s Device.
Step 5: Additional checks and clean-ups
We don’t yet have a logic on how we decide if we want to download the new model. In this example, we’ll do something very basic: each model’s file-name is a unique UUID. All we need to do is to check if a model under the exact file name is available locally:
private func downloadIfNeeded(from url: URL) async throws {
let lastPathComponent = url.lastPathComponent
// Check if the model file already exists (for this sample project we use the unique file name as identifier)
if let localFiles = try? fileManager.contentsOfDirectory(at: modelsFolder, includingPropertiesForKeys: nil),
localFiles.contains(where: { $0.lastPathComponent == lastPathComponent }) {
// File exists, you could add a version check here if versions are part of the file name or metadata
print("Model already exists locally. No need to download.")
} else {
let downloadedURL = try await downloadCoreMLFile(from: url) // File does not exist, download it
let compiledURL = try compileCoreMLFile(at: downloadedURL)
try deleteAllOutdatedModels(keeping: compiledURL.lastPathComponent)
print("Model downloaded, compiled, and old models cleaned up successfully.")
}
}
Of course we want to be a good citizen, and delete all older models from the local storage. Also, for this sample project, this is required, as we’re using UUIDs for versioning, meaning the iOS client actually doesn’t know about which version is higher. For sophisticated systems it’s quite common to not have this transparency to the client, as the backend may be running multiple experiments and challenger models in parallel across all clients.
private func deleteAllOutdatedModels(keeping recentModelFileName: String) throws {
let urlContent = try fileManager.contentsOfDirectory(at: modelsFolder, includingPropertiesForKeys: nil, options: .skipsHiddenFiles)
for fileURL in urlContent where fileURL.lastPathComponent != recentModelFileName {
try fileManager.removeItem(at: fileURL)
}
}
Step 6: Execute the newly downloaded CoreML file instead of the bundled version
Now all that’s left is to automatically switch between the CoreML file that we bundled within our app, and the file we downloaded from our servers, whereas we’d always want to prefer the one we downloaded remotely.
In our ModelDownloadManager, we want an additional function that exposes the model we want to use. This can either be the bundled CoreML model, or the CoreML model downloaded most recently over-the-air
internal func latestModel() -> MyFirstCustomModel? {
let fileManagerContents = (try? fileManager.contentsOfDirectory(at: modelsFolder, includingPropertiesForKeys: nil)) ?? []
if let latestFileURL = fileManagerContents.sorted(by: { $0.lastPathComponent > $1.lastPathComponent }).first,
let otaModel = try? MyFirstCustomModel(contentsOf: latestFileURL) {
return otaModel
} else if let bundledModel = try? MyFirstCustomModel(configuration: MLModelConfiguration()) {
return bundledModel // Fallback to the bundled model if no downloaded model exists
}
return nil
}
There are almost no changes needed to our code base from part 1.
Instead of using the MyFirstCustomModel initializer directly, we now need to use the newly created .latestModel() method.
let batteryLevel = UIDevice.current.batteryLevel
let batteryCharging = UIDevice.current.batteryState == .charging || UIDevice.current.batteryState == .full
do {
let modelInput = MyFirstCustomModelInput(input: [
Double(batteryLevel),
Double(batteryCharging ? 1.0 : 0.0)
])
if let currentModel = modelDownloadManager.latestModel(),
let modelMetadata = currentModel.model.modelDescription.metadata[.description] {
let result = try currentModel.prediction(input: modelInput)
let classProbabilities = result.featureValue(for: "classProbability")?.dictionaryValue
let upsellProbability = classProbabilities?["Purchased"]?.doubleValue ?? -1
showAlertDialog(message:("Chances of Upsell: \(upsellProbability), executed through model \(modelMetadata)"))
} else {
showAlertDialog(message:("Could not run CoreML model"))
}
} catch {
showAlertDialog(message:("Error running CoreML file: \(error)"))
}
Step 7: Decide when you want to trigger the update check
The only remaining code that’s left: triggering the update check. When you do that will highly depend on your app, and the urgency in which you want to update your models.
Task {
do {
try await modelDownloadManager.checkForModelUpdates()
showAlertDialog(message:("Model update completed successfully."))
} catch {
// Handle possible errors here
showAlertDialog(message:("Failed to update model: \(error.localizedDescription)"))
}
}
Demo App
As part of this series, we’ve built out a demo app that shows all of this end-to-end in action. You can find it available here on GitHub: https://github.com/KrauseFx/CoreMLDemo:
What’s next?
Today we’ve covered how you can roll out new machine learning models directly to your users’ iPhones, running them directly on their ML-optimized hardware. Using this approach you can make decisions on what type of content, or prompts you show based on the user’s context, powered by on-device machine learning execution. Updating CoreML files quickly, on-the-fly without going through the full App Store release cycle is critical, to quickly react to changing user-behaviors, when introducing new offers in your app, and to constantly improve your app, be it increasing your conversion rates, reducing annoyances and churn, or optimizing other parts of your app.
This is just the beginning: Next up, we will talk about how to manage the rollout of new ML models, in particular:
- How to safely rollout new models: monitor, pause or rollback faulty models
- How to monitor performance of deployed models
- How to reliably compare performance between models, and the baseline performance
Excited to share more on what we’ve learned when building ContextSDK to power hundreds of machine learning models distributed across more than 25 Million devices.
Note: This is a cross-post of the original publication on contextsdk.com.
Tags: ios, context, sdk, swift, coreml, machine learning, sklearn, mlmodel, ota, over-the-air, remote, update | Edit on GitHub
How to train your first machine learning model and run it inside your iOS app via CoreML
Note: This is a cross-post of the original publication on contextsdk.com.
Introduction
Machine Learning (ML) in the context of mobile apps is a wide topic, with different types of implementations and requirements. On the highest levels, you can distinguish between:
- Running ML models on server infrastructure and accessing it from your app through API requests
- Running ML models on-device within your app (we will focus on this)
- Fine-tuning pre-trained ML models on-device based on user behavior
- Training new ML models on-device
As part of this blog series, we will be talking about variant 2: We start out by training a new ML model on your server infrastructure based on real-life data, and then distributing and using that model within your app. Thanks to Apple’s CoreML technology, this process has become extremely efficient & streamlined.
We wrote this guide for all developers, even if you don’t have any prior data science or backend experience.
Step 1: Collecting the data to train your first ML model
To train your first machine learning model, you’ll need some data you want to train the model on. In our example, we want to optimize when to show certain prompts or messages in iOS apps.
Let’s assume we have your data in the following format:
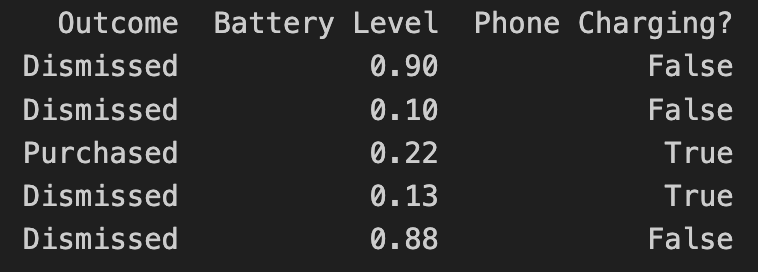
- Outcome describes the result of the user interaction, in this case, if they purchased an optional premium upgrade
- Battery Level is the user’s current battery level as a float
- Phone Charging defines if the phone is currently plugged in as a boolean
In the above example, the “label” of the dataset is the outcome. In machine learning, a label for training data refers to the output or answer for a specific instance in a dataset. The label is used to train a supervised model, guiding it to understand how to classify new, unseen examples or predict outcomes.
How you get the data to train your model is up to you. In our case, we’d collect non-PII data just like the above example, to train models based on real-life user behavior. For that we’ve built out our own backend infrastructure, which we’ve already covered in our Blog:
- Building the Infrastructure to Ingest 40m Context Events per Day
- Unifying Data Models Across a Heterogeneous Stack
Step 2: Load and prepare your data
There are different technologies available to train your ML model. In our case, we chose Python, together with pandas and sklearn.
Load the recorded data into a pandas DataFrame:
import pandas as pd
rows = [
['Dismissed', 0.90, False],
['Dismissed', 0.10, False],
['Purchased', 0.24, True],
['Dismissed', 0.13, True]
]
data = pd.DataFrame(rows, columns=['Outcome', 'Battery Level', 'Phone Charging?'])
print(data)
Instead of hard-coded data like above, you’d access your database with the real-world data you’ve already collected.
Step 3: Split the data between training and test data
To train a machine learning model, you need to split your data into a training set and a test set. We won’t go into detail about why that’s needed, since there are many great resources out there that explain the reasoning, like this excellent CGP Video.
from sklearn.model_selection import train_test_split
X = data.drop("Outcome", axis=1)
Y = data["Outcome"]
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, shuffle=True)
The code above splits your data by a ratio of 0.2 (⅕) and separates the X and the Y axis, which means separating the label (“Outcome”) from the data (all remaining columns).
Step 4: Start Model Training
As part of this step, you’ll need to decide on what classifier you want to use. In our example, we will go with a basic RandomForest classifier:
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
classifier = RandomForestClassifier()
classifier.fit(X_train, Y_train)
Y_pred = classifier.predict(X_test)
print(classification_report(Y_test, Y_pred, zero_division=1))
The output of the above training will give you a classification report. In simplified words, it will tell you more of how accurate the trained model is.
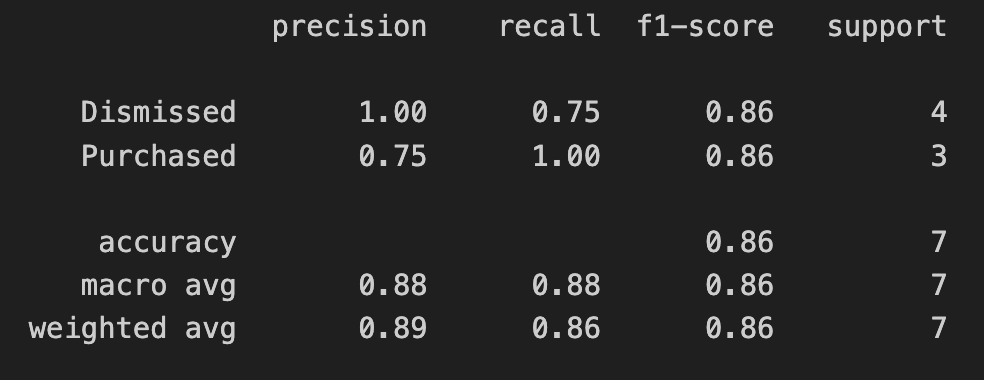
In the screenshot above, we’re only using test data as part of this blog series. If you’re interested in how to interpret and evaluate the classification report, check out this guide).
Step 5: Export your model into a CoreML file
Apple’s official CoreMLTools make it extremely easy to export the classifier (in this case, our Random Forest) into a .mlmodel (CoreML) file, which we can run on Apple’s native ML chips. CoreMLTools support a variety of classifiers, however not all of them, so be sure to verify its support first.
import coremltools
coreml_model = coremltools.converters.sklearn.convert(classifier, input_features="input")
coreml_model.short_description = "My first model"
coreml_model.save("MyFirstCustomModel.mlmodel")
Step 6: Bundle the CoreML file with your app
For now, we will simply drag & drop the CoreML file into our Xcode project. In a future blog post we will go into detail on how to deploy new ML models over-the-air.
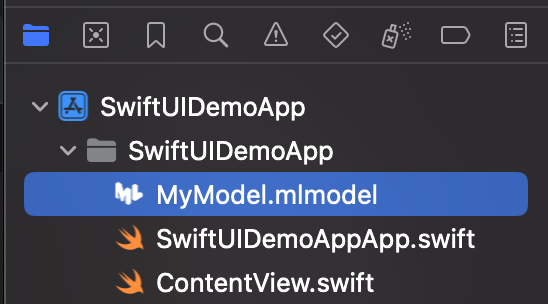
Once added to your project, you can inspect the inputs, labels, and other model information right within Xcode.
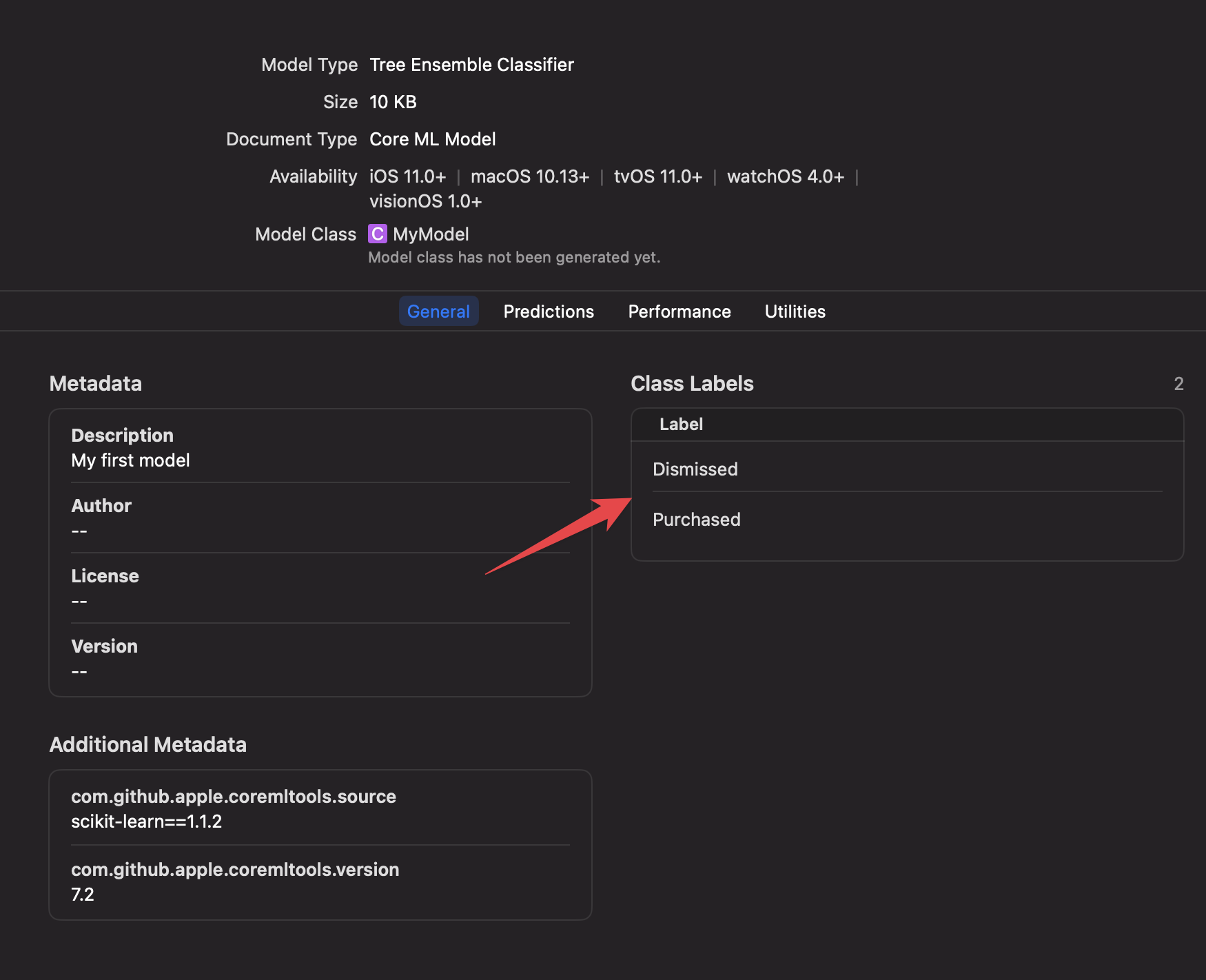
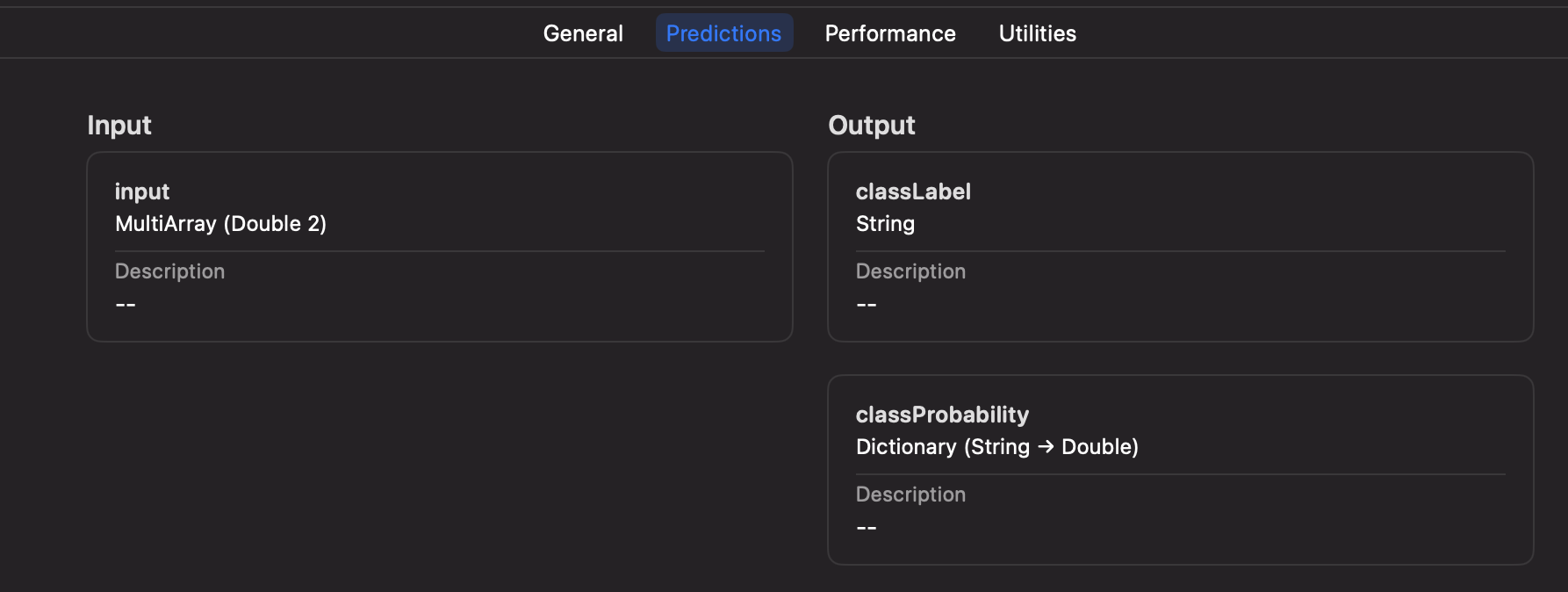
Step 7: Executing your Machine Learning model on-device
Xcode will automatically generate a new Swift class based on your mlmodel file, including the details about the inputs, and outputs.
let batteryLevel = UIDevice.current.batteryLevel
let batteryCharging = UIDevice.current.batteryState == .charging || UIDevice.current.batteryState == .full
do {
let modelInput = MyFirstCustomModelInput(input: [
Double(batteryLevel),
Double(batteryCharging ? 1.0 : 0.0)
])
let result = try MyFirstCustomModel(configuration: MLModelConfiguration()).prediction(input: modelInput)
let classProbabilities = result.featureValue(for: "classProbability")?.dictionaryValue
let upsellProbability = classProbabilities?["Purchased"]?.doubleValue ?? -1
print("Chances of Upsell: \(upsellProbability)")
} catch {
print("Error running CoreML file: \(error)")
}
In the above code you can see that we pass in the parameters of the battery level, and charging status, using an array of inputs, only identified by the index. This has the downside of not being mapped by an exact string, but the advantage of faster performance if you have hundreds of inputs.
Alternatively, during model training and export, you can switch to using a String-based input for your CoreML file if preferred.
We will talk more about how to best set up your iOS app to get the best of both worlds, while also supporting over-the-air updates, dynamic inputs based on new models, and how to properly handle errors, process the response, manage complex AB tests, safe rollouts, and more.
Conclusion
In this guide we went from collecting the data to feed into your Machine Learning model, to training the model, to running it on-device to make decisions within your app. As you can see, Python and its libraries, including Apple’s CoreMLTools, make it very easy to get started with your first ML model. Thanks to native support of CoreML files in Xcode, and executing them on-device, we have all the advantages of the Apple development platform, like inspecting model details within Xcode, strong types and safe error handling.
In your organization, you’ll likely have a Data Scientist who will be in charge of training, fine-tuning and providing the model. The above guide shows a simple example - with ContextSDK we take more than 180 different signals into account, of different types, patterns, and sources, allowing us to achieve the best results, while keeping the resulting models small and efficient.
Within the next few weeks, we will be publishing a second post on that topic, showcasing how you can deploy new CoreML files to Millions of iOS devices over-the-air within seconds, in a safe & cost-efficient manner, managing complicated AB tests, dynamic input parameters, and more.
Update: Head over to the second post of the ML series
Tags: ios, context, sdk, swift, coreml, machine learning, sklearn, mlmodel | Edit on GitHub
Launching Context Insights
In the world of mobile app development, understanding the user is key to creating experiences that resonate and retain. Today, we’re thrilled to introduce Context Insights, a brand new analytics tool designed from the ground up for iOS developers. Context Insights is your gateway to understanding the real-world contexts in which your users engage with your app.
A New Dimension of User Understanding
iOS apps are used in a multitude of circumstances, at home on the couch, during the commute, while out on a walk, or anywhere in-between. Context Insights offers a new approach to user analytics. By analyzing the real-world context of your user base, you can gain insights into how different situations influence app usage. This allows you to segment your users more meaningfully, according to the context in which they interact with your app, providing a deeper understanding of their behavior and preferences.
Unparalleled Ease of Integration
We know how precious development time is. That’s why we’ve made integrating Context Insights into your iOS app as simple as possible. You’re just three steps away from getting brand new insights into how your app is used.
Step 1 - Signup and get your license key
Head over to our signup page and create a free account. We will send you your license key via email immediately.
Step 2 - Download ContextSDK and integrate it into your app
Simply add ContextSDK as a dependency to your Podfile (other integration options are supported as well, see here) and activate it by adding a single line at app start:
import ContextSDK
ContextManager.setup("YOUR_LICENSE_KEY")
Step 3 - Ship an Update
After the super simple integration simply ship an update to the App Store and we will notify you as soon as your insights are ready.
Designed with Performance in Mind
Context Insights is designed to ensure a negligible impact on your app’s performance. Adding less than 700KB to your app’s footprint. Moreover, it operates using less than 1MB of memory while active, ensuring that your apps performance is unaffected.
Privacy First
Finally it’s worth noting that Context Insights has been designed from the ground up to preserve your users privacy. We don’t require the user to authorize tracking, nor do we require any additional permissions to work. All the data collected by Context Insights is non PII (Personally Identifiable Information) and as such doesn’t not fall under GDPR.
Get Started Today
Embark on a journey to deeply understand your users with Context Insights. By integrating this powerful tool, you’re not just enhancing your app; you’re elevating the entire user experience. Discover the untapped potential within your user base and let Context Insights guide you towards creating more engaging, personalized, and successful iOS applications.
We can’t wait to see how you leverage Context Insights to make your app truly exceptional. Welcome to the future of iOS app development.
Get started here or get more details on how it works on our landing page.
Tags: ios, context, sdk, swift, insights, analytics | Edit on GitHub
Automatically build & distribute custom iOS SDK Binaries for each customer
Note: This is a cross-post of the original publication on contextsdk.com.
Introduction
This is a follow-up post to our original publication: How to compile and distribute your iOS SDK as a pre-compiled xcframework.
In this technical article we go into the depths of best practices around
- How to automate the deployment of different variants of your SDK to provide a fully customized, white-glove service for your customers
- How this approach allows your SDK to work offline out-of-the box right from the first app start
Build Automation
For everyone who knows me, I love automating iOS app-development processes. Having built fastlane, I learned just how much time you can save, and most importantly: prevent human errors from happening. With ContextSDK, we fully automated the release process.
For example, you need to properly update the version number across many points: your 2 podspec files (see our last blog post), your URLs, adding git tags, updating the docs, etc.
Custom binaries for each customer
With ContextSDK, we train and deploy custom machine learning models for every one of our customers. The easiest way most companies would solve this is by sending a network request the first time the app is launched, to download the latest custom model for that particular app. However, we believe in fast & robust on-device Machine Learning Model execution, that doesn’t rely on an active internet connection. In particular, many major use-cases of ContextSDK rely on reacting to the user’s context within 2 seconds after the app is first launched, to immediately optimize the onboarding flow, permission prompts and other aspects of your app.
We needed a way to distribute each customer’s custom model with the ContextSDK binary, without including any models from other customers. To do this, we fully automated the deployment of custom SDK binaries, each including the exact custom model, and features the customer needs.
Our customer management system provides the list of custom SDKs to build, tied together with the details of the custom models:
[
{
"bundle_identifiers": ["com.customer.app"],
"app_id": "c2d67cdb-e117-4c3e-acca-2ae7f1a42210",
"customModels": [
{
"flowId": 8362,
"flowName": "onboarding_upsell",
"modelVersion": 73
}, …
]
}, …
]
Our deployment scripts will then iterate over each app, and include all custom models for the given app. You can inject custom classes and custom code before each build through multiple approaches. One approach we took to include custom models dynamically depending on the app, is to update our internal podspec to dynamically add files:
# ...
source_files = Dir['Classes/**/*.swift']
if ENV["CUSTOM_MODEL_APP_ID"]
source_files += Dir["Classes/Models/Custom/#{ENV["CUSTOM_MODEL_APP_ID"]}/*.mlmodel"]
end
s.source_files = source_files
# ...
In the above example you can see how we leverage a simple environment variable to tell CocoaPods which custom model files to include.
Thanks to iOS projects being compiled, we can guarantee integrity of the codebase itself. Additionally we have hundreds of automated tests (and manual tests) to guarantee alignment of the custom models, matching SDK versions, model versions and each customer’s integration in a separate, auto-generated Xcode project.
Side-note: ContextSDK also supports over-the-air updates of new CoreML files, to update the ones we bundle the app with. This allows us to continuously improve our machine learning models over-time, as we calibrate our context signals to each individual app. Under the hood we deploy new challenger-models to a subset of users, for which we compare the performance, and gradually roll them out more if it matches expectations.
Conclusion
Building and distributing a custom binary for each customer is easier than you may expect. Once your SDK deployment is automated, taking the extra step to build custom binaries isn’t as complex as you may think.
Having this architecture allows us to iterate and move quickly, while having a very robust development and deployment pipeline. Additionally, once we segment our paid features for ContextSDK more, we can automatically only include the subset of functionality each customer wants enabled. For example, we recently launched AppTrackingTransparency.ai, where a customer may only want to use the ATT-related features of ContextSDK, instead of using it to optimise their in-app conversions.
If you have any questions, feel free to reach out to us on Twitter or LinkedIn, or subscribe to our newsletter on contextsdk.com.
Note: This is a cross-post of the original publication on contextsdk.com.
Tags: ios, context, sdk, swift, xcframework, compile, distribute, automation, fastlane, custom | Edit on GitHub